posted 03-12-2008 12:44 PM

Thanks Dan,That was a helpful summary.
The tendency to think of someone as "up-on" or "in-the-know" regarding a topic, just because they've been around for a long time, published some important stuff, or wear expensive boots is yet another example of professional imprinting, and should be avoided. This is yet another example of the need for every professional to read both the standards of practice (locally and nationally) and the journal literature. I'm not suggesting anyone is not knowlegeable, just that we all need to read and think for ourselves.
There is still an awful lot that we don't know about PCSOT, and there is a tendency to want to fill in the blanks with something we just made up - just so that we have an answer. Unfortunately, this approach will not impress our adversaries.
Surprisingly little research is occurring regarding PCSOT, and our detractors and oppontents are taking note of that. What you'll see happening, aside from the occassional helpful things like Offe & Offe 2007, is a steady stream of critical and damaging statements in publications from knowledgable and respected persons.
Simple appeals to fear and morality will achieve only temporary victory. Charisma and forceful personalities will not answer the questions of scientists. The long-term solution will be to align our practices with research from risk assessment and risk-management, and not attempt to sway the hearts and minds of scientists and policy makers by making stuff up without proof in the form of sound theory that is cogent with other knowledge, and of course evidence in the form of data.
I would invite anyone to pose an argument about how DI/NSR is more consistent with screening test theory than SR/NSR.
------------------
And now for a thought experiment, and some math.
The LEPET standards, at my last reading, allow for up to five (5) RQs.
We assume that most people are normal in most aspects, because "normal," by definition, is whatever most people are. We then assume they are normal in terms of honesty and integrity, and lifestyle activities. Remember that by "normal" we don't mean a value-based version of normality; we mean "within the normal range," or "within normal limits" when compared to lots of other people from similar socioeconomic, developmental, and cultural backgrounds.
Gaussian theory tells us that 68% of all persons, when evaluating normally distributed data or phenomena, will be within one standard deviation of the population mean, and 95% of all persons will be within 2 standard deviantions. The "normal range" is commonly defined as the wo-standard-deviation range. Therefore 95% of all people are "normal" (i.e., within the normal range, or within normal limits). Only 5% of persons will be considered non-normal, or outside the normal range. This is the basis of the statements of some professionals that delinquency among juveniles is "normal." So 2.5% of persons will be involved in more-than-normal ammoungs of deliquency, and 2.5% of persons can be expected to be involved in a lot less delinquency than those in the normal range.
For some purposes, we use a more conservative normal range of 1 standard deviation, with tells us that 16% of people will be overinvolved in a certain normal activity, and 16% will be underinvolved. We call this a two-tailed experiment, because of the thin tail regions of the dreaded bell curve or normal distribution.
In PCSOT we should be concerned about both tail regions, because that would help us identify persons of low and high risk levels.
In LEPET testing we are really interested in only those persons in one tail region (low risk persons). In a one-tailed experiment, the 84th and 97.5th percentile represent the one standard deviation and two-standard deviation boundaries. What this means is that everyone under the 84th or 97.5th percentile, depending on your tolerance for risk, might not be considered low risk.
So, lets image we are testing police applicants for their history of honesty and integrity: crimes against persons, property crimes, drug use, unlawful sexual activities, and maybe gambling (I don't really know what LEPET targets are - these are what I would, at first thought, imagine as informative for a psychological or risk evaluator)
In mixed-issue screening tests, the RQs are independent. That is, it is conceivable that a person could be deceptive to one or more test questions while being truthful to others. This is conceptual only, and does not imply that mathematical or testing theory can accurate parse both SR and NSR results in a single examination. The statistical principle at work with independent testing targets is called the "multiplication rule." This rule underlies Bayesian theory, and is why paired testing (Marin protocol) is effective. With the multiplication-rule, we estimate the number of anticipated truthful persons, by taking the inverse of the base-rate as the estimated non-deceptive rate, and multiplying that value for each of the investigation targets (RQs). You can see the table below, that when the base-rate is over 15%, for 4 investigation targets, the number of truthful persons falls to 50% or lower. When base-rates are higher, the proportion of truthful persons falls even lower.
It does not surprise me to read at anti-P that some pre-employment screening programs (perhaps those with rigorous standards) have higher rates of failure.
Now factor in what we can estimate about inconclusive rates...
With INC, the statistical priciple at work is not the multiplication-rule, but he "addition-rule" for dependent probability events. Relevant question targets in mixed-issues screening polygraphs are NOT independent regarding INC results. That is because the only unambiguous resolution of a mixed issues exam is when the subject is NSR to all questions. There for any INC response to any target means the test is INC, unless there is something that is SR, in which case all-bets-are-off with everything else that isn't also SR.
With the addition-rule, we add (duh) the estimated INC rate for each distinct investigation target, because any INC result sinks the test.
You can see that INC estimates go up with the number of RQs. These are mathematical realities.
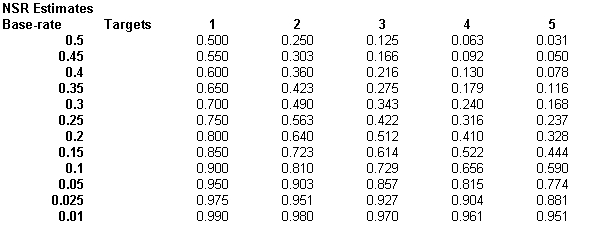
Here is a table of estimates for NSR rates assuming

The solution is not to borrow point or push scores. The solution is to use more advanced statistical procedures which off greater power than the blunt methods we use in present handscoring systems.
Below is a graphic illustrating the results of the OSS training sample, using spot-scoring rules - for which the addition rule plays an important role in the occurrence of INC results. We don't really use spot scoring with ZCT exams, but the data illustrate the point. Using Spot rules, gives 26.7% INC compared with 7.2% INC using two-stage rules.

The point of all this is that we have an obligation to formulate our expections and policies for test performance around an accurate understanding of the mathematical principles that define how and why tests work and what the real limitations are.
r

------------------
"Gentlemen, you can't fight in here. This is the war room."
--(Stanley Kubrick/Peter Sellers - Dr. Strangelove, 1964)


 Polygraph Place Bulletin Board
Polygraph Place Bulletin Board